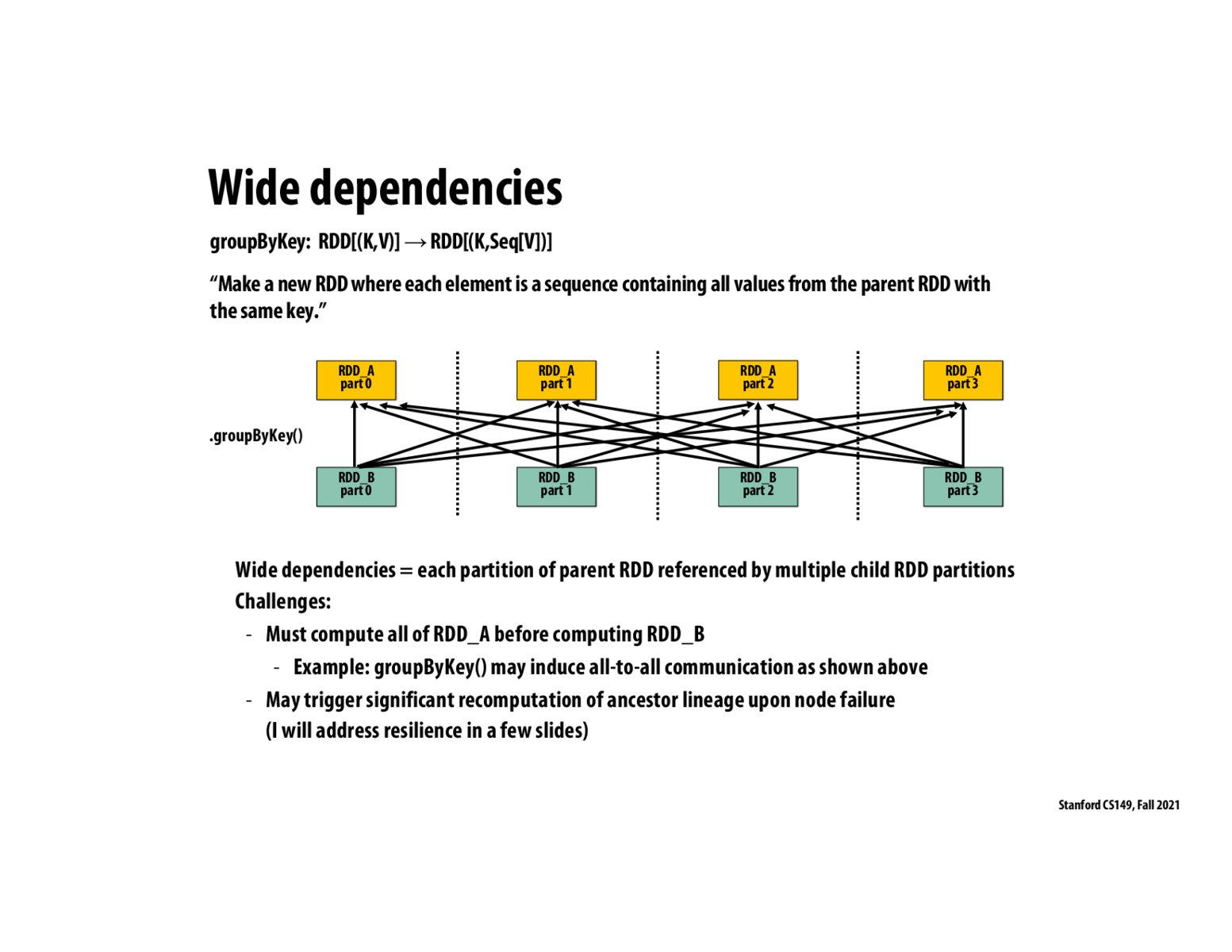


Seems about right. I understand that narrow dependencies are those in which execution of RDDs in a node is dependent (if at all) on other computations within that same node and not in any other node. Such RDDs can be fused and run on the same node correctly. Wide dependencies are dependencies across nodes. Like your sorting example in cases where the data is partitioned to be executed across different nodes. In the end, the results must move across nodes to complete the computation.

How is running an RDD transformation with wide dependencies possible? My understanding was that transformations are done on RDDs which should return a subset of the original RDD. How is it possible to run a transformation like GroupByKey on an RDD without having access to other RDDs (and therefore not being able to use GroupByKey)?

In which use cases would going for wide dependencies make more sense than narrow ones given that all the dependencies means lot of movement across nodes?

I believe that it's a general strategy to stay with narrow dependencies, especially since that's a major step in mapreduce. An analogy to this would be data localization when designing parallel programs, like when we talked about how to share data when solving PDEs.

@potato I think wide dependencies vs. narrow dependencies often has more to do with the application and may be unavoidable. If you want to .toLower() an entire book, you only need to worry about narrow dependencies. I think anything involving grouping by key is going to involve nodes that depend on more than just one parent node.
Please log in to leave a comment.
I'm still a little confused by partitions in spark. Is the idea that things like sorting require to be run together. So do all the parts get moved to a single machine?