Back to Lecture Thumbnails

gohan2021

kristinayige
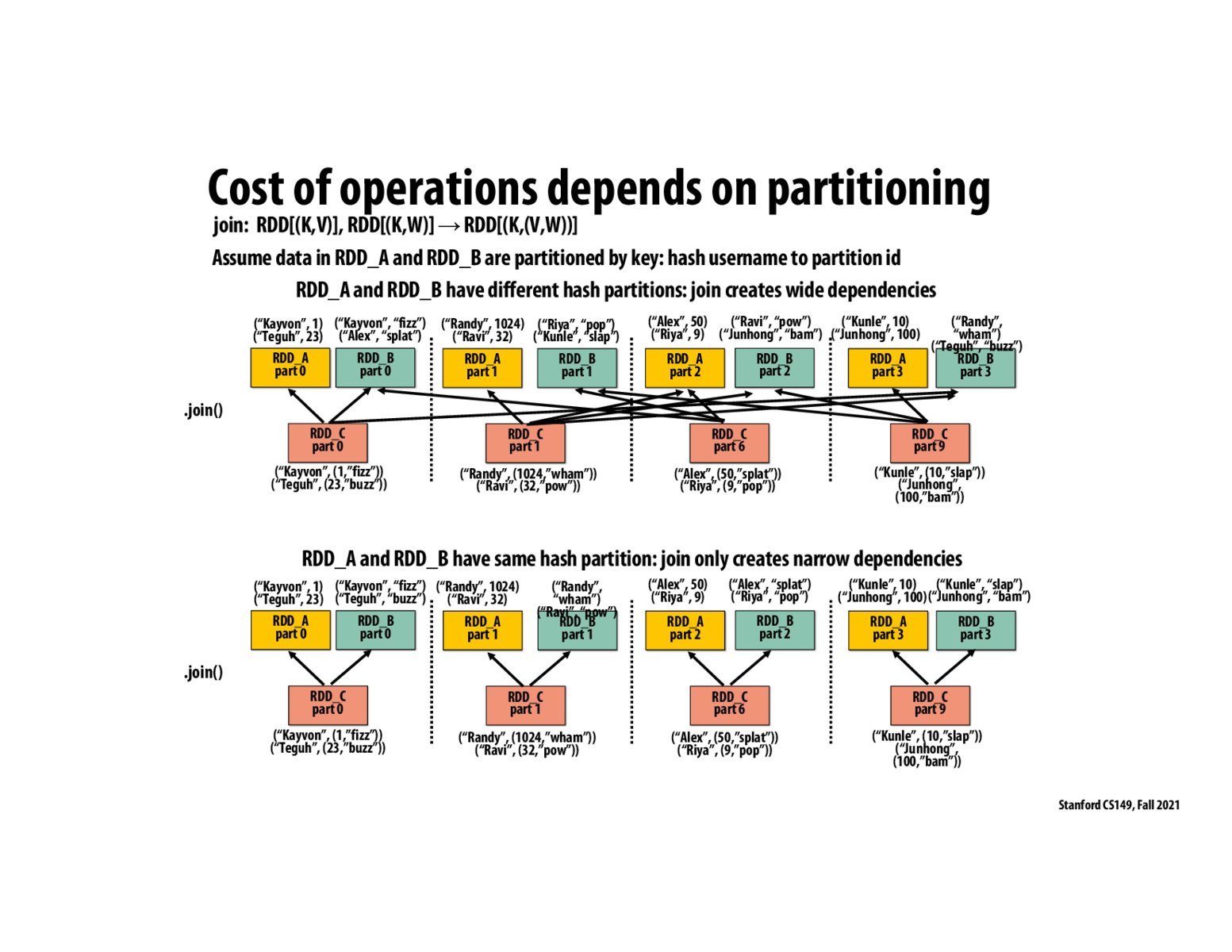
Can we conclude that the dependencies between RDD parts for sort/group functions make them more expensive than map/filter?

pizza
@kristinayige, from my understanding, yes. I think that's what the hash partitioner (on the next slide) is trying to resolve, by creating narrow dependencies from the partitioning. This isn't helpful/needed with map/filter because they're already narrowly dependent.

mark
Would there be cases where the cost of partitioning data onto the same nodes before operating is not worth the cost of moving the data around?
Please log in to leave a comment.
Does Spark utilize caches efficiently? It seems that these partition calls might generate cache flushes across the nodes. How to balance between workload's data locality and cache churn?
Also, I would like to understand how Spark would work on an environment like GPU. Would Spark's language functions be translated into GPU's shader calls that run on many cores on the GPU for data processing?