

The central node detects node failures through a heartbeat mechanism. Every node is supposed to periodically send a heartbeat ping message to the central node. If this message is not received from a particular node, the central node would consider it to be failed and rerun its tasks on some other node.

What's the performance penalty on such failures? E.g. if my RDDs are larger (requiring more nodes), does it mean the probability of any node failing would be higher for my operations, and potentially making my operations less performant?

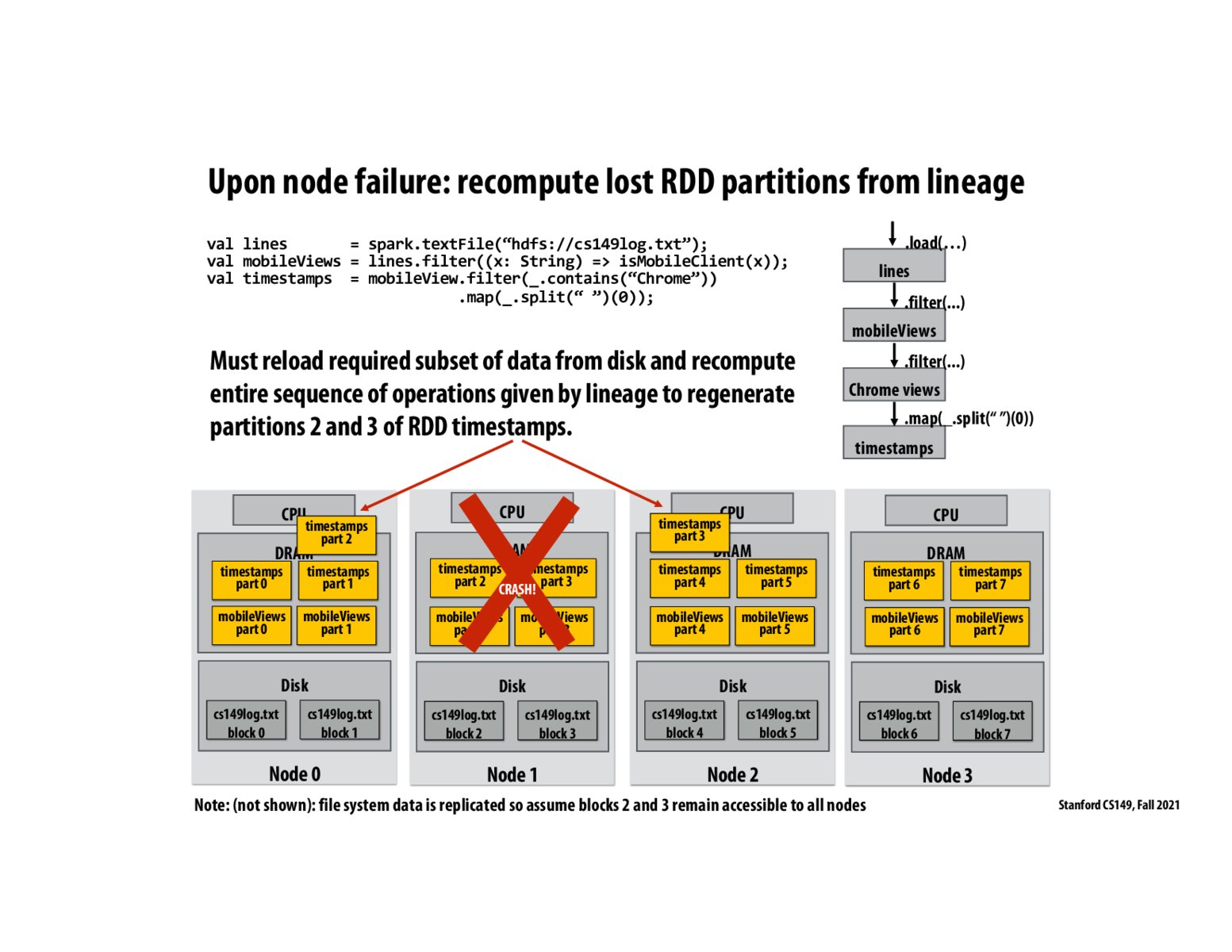
I am unclear on how the data is going to be transferred from one node to another upon failure. How will the node that failed do anything?

^ The failed node is considered inactive from Spark perspective. So the RDD parts assigned to the failed node will be distributed to the remaining nodes. The disk data will also be available because they are replicated on other nodes

This is a good website to learn more about spark fault tolerance. https://data-flair.training/blogs/fault-tolerance-in-apache-spark/
Please log in to leave a comment.
How do the other nodes know which partitions need to be reloaded?