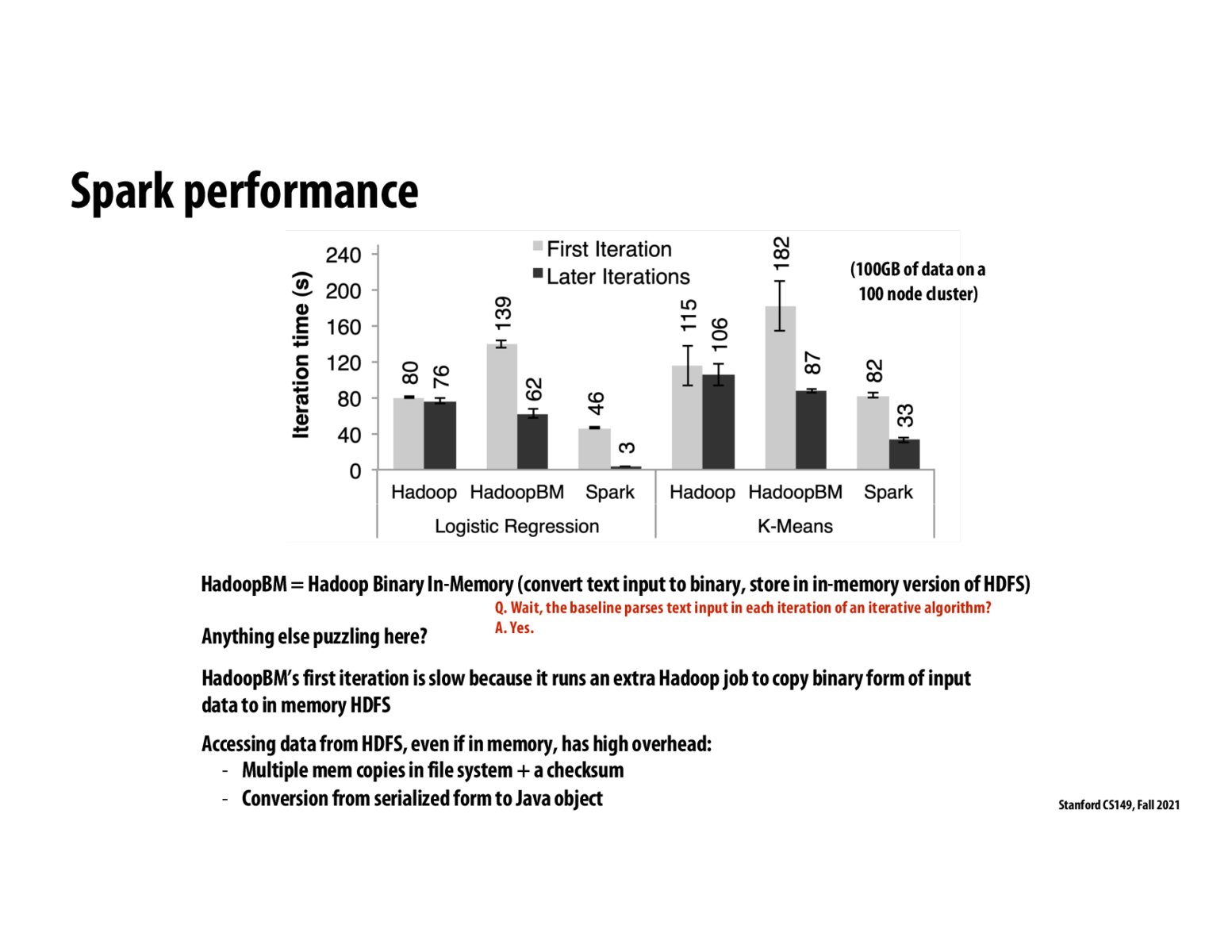


I'm still a little confused on why Spark is so much faster, similar to @juliewang's question above. I'm not sure exactly what Spark keeps in memory and what it saves to maintain fault-tolerance and be so much faster. Is the main difference between Spark and these other frameworks that Spark only needs to keep track of the lineage, whereas Hadoop and others actually backup intermediary computations to storage each time? I can imagine this would account for the speedup - but at the same time, I can also see recomputing the lineage of functions any time we need access to an intermediary RDD to be quite high overhead as well.

@probreather101 The main difference is that the entire dataset is kept in memory. This means you can avoid expensive disk reads on the distributed file system.

@juliewang I believe the original data is stored on disk.
Please log in to leave a comment.
If subsequent iterations by Spark are fast, does that mean that the loaded data is stored in memory? If that's the case does this mean that nodes always have 3 * data subset they're responsible for? A copy of the original data, a copy of the parent partition, and a copy of the child partition being calculated on the parent?