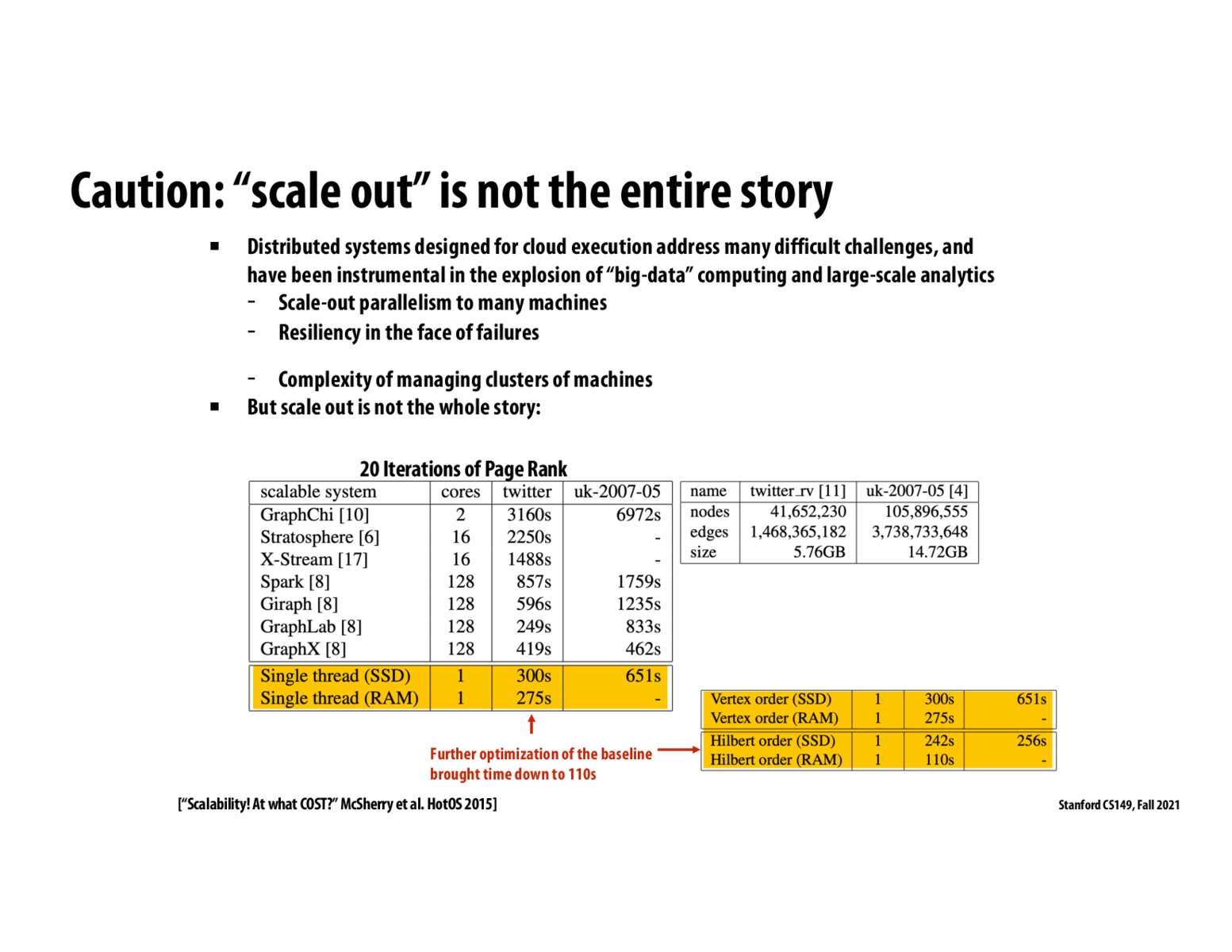


@csmith23, I do not think it is that the cores are sitting completely idle, but that scalable implementations of some algorithms are not nearly as efficient as single-core/threaded implementations.
The paper [1] brings up some interesting anecdotes, for example, that the most common distributed way of computing connectivity is "label propagation," where vertices iteratively update their labels based on their neighbors labels. Updates are commutative and associative, so they naturally lend themselves well to scalable implementations. However, this algorithm is not the most efficient or naturally fastest way to compute connectivity, it's just the one that scales best. A similar situation occurs for union-find (pg. 4 of the paper), where a label-propagation approach simply does more work than a standard algorithm.
I think the overarching point of the paper is that any system can be made to scale well with a sub-par single-threaded implementation, and more work needs to be done to ensure that scaling does not come at the cost of real-world performance.
[1] https://www.usenix.org/system/files/conference/hotos15/hotos15-paper-mcsherry.pdf
Please log in to leave a comment.
does this imply that most of the cores in the scalable systems were sitting idling for most of the compute time? is there any data measuring that?