

a deep neural network is a feedforward neural network with many layers.

@shivalgo agreed! I'd be very interested in seeing the types of speedups we can get with parallelization in this domain, especially how the speedups scale with the number of available threads. I'm also curious about the state of the art in terms of algorithm design in this domain. I imagine parallelization is already widespread, but is there still untapped potential? Where do we go from here?

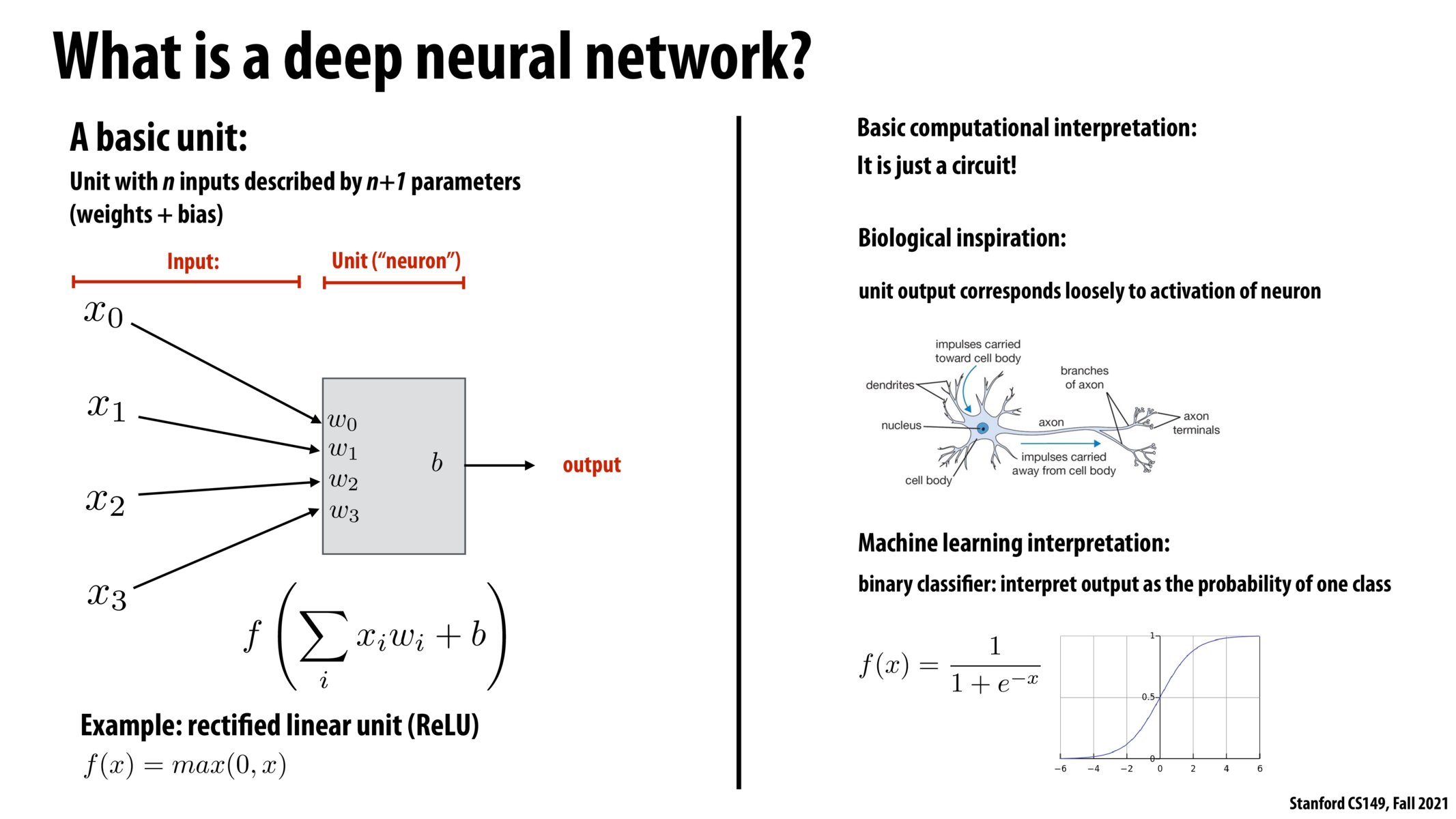
Is the extra (+1) parameter the 'b' inside the unit?

@sanjayen I think that a lot of the inefficiency actually comes from how memory is handled. A lot of ML algorithms are often memory bound and figuring out how to reduce this is where a lot of untapped potential exists.

what i've gotten out of all my AI courses: a neural net is a sequence of alternating linear transformations (i.e. matrix multiply) and non-linearities (i.e. softmax)
also which pronunciation of ReLU is more common? in 231N they always said "rel-U" but kayvon said "ree-lu"
Please log in to leave a comment.
Computing such inner products on vectors-matrices or matrix-matrix is why we need parallelization algorithms to work at super fast speeds. Because there are billions of flops from these inner products in the large DNNs.