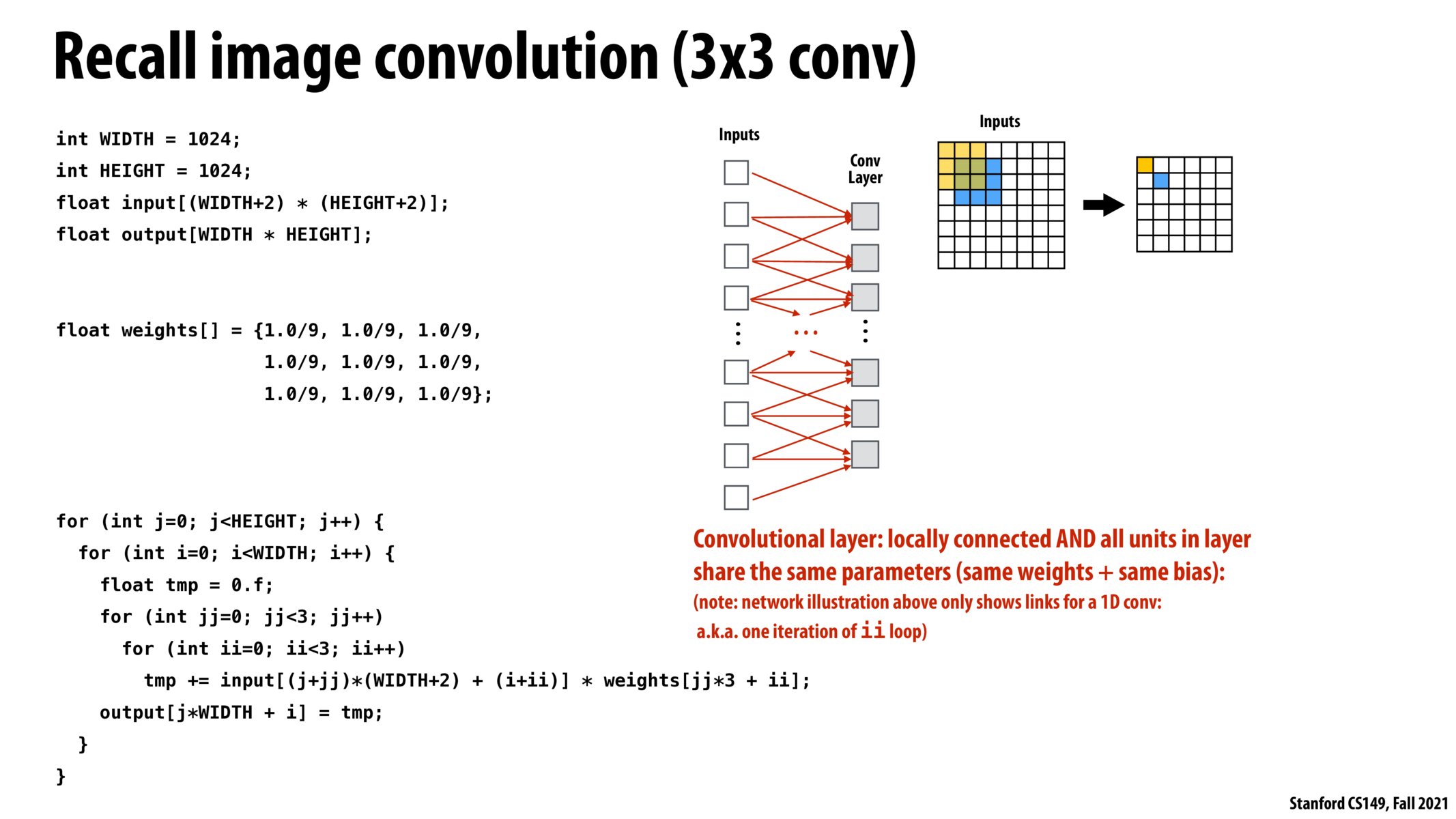


@tigerpanda, removing the padding on all sides, and just doing blurring using the original image is equivalent to removing the borders of a blurred image with padding. We are losing some of the information at the edges of the original image.
Zero-padding in convolutional networks has the additional benefit of allowing us to control the output size of a conv. layer, which is often used to ensure the layer input and output are the same size.
These CS 231n course notes https://cs231n.github.io/convolutional-networks/ have more information on padding.

@tigerpanda It seems like the results are the same. In WA5, the padding is done on all of the borders of the original image. There is actually no "pixel of interest" in the output, only storing the summed-up information of a range of pixels (size of the filter) to a targeted location, which is fresh. The example above also seems like storing to the upper left corner.

If anyone is interested in learning more about convolutional arithmetic for deep learning, there's an excellent resource here - https://arxiv.org/pdf/1603.07285.pdf. It goes into a fair amount of depth and it would be cool to analyze these operations through the lens of CS149.
Please log in to leave a comment.
If I remember correctly from WA5, the convolution we did for a single pixel did not take the average of the pixels bordering it but rather the pixel of interest was in the upper left hand corner and all of the values averaged in the convolution were to the right and down of it. How does this format vs centering around the pixel affect the output? For example, if we are doing a blur on the image, how would this selection of which pixels around the pixel of interest to average to create the blur play into the final output of our image?