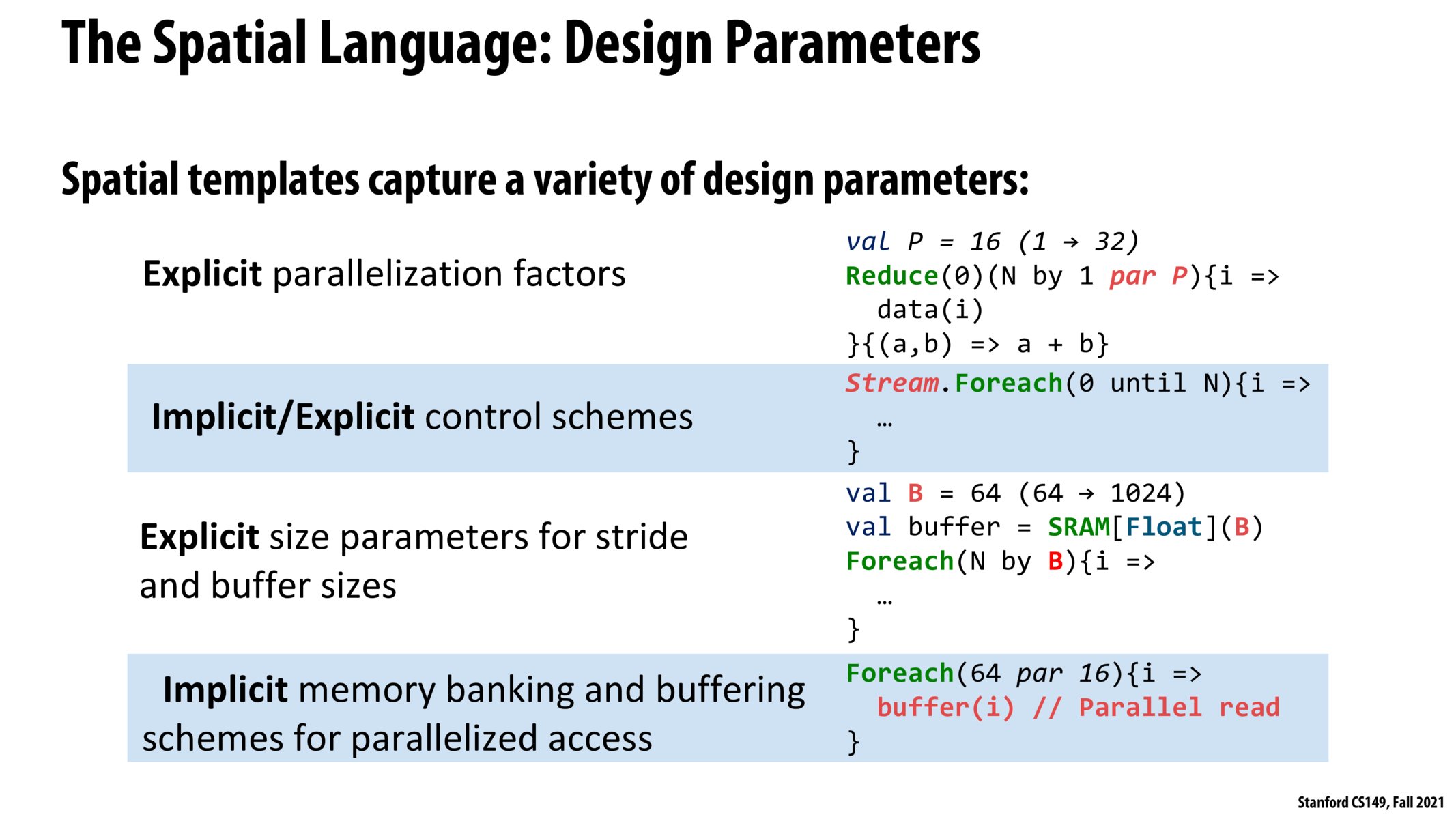


Do these templates support both static and dynamic assignment? Upon first glance it seems like these are all static assignment operators so are there other ways we can call dynamic assignment>

Going on a limb here, but could one argue that the distinction between Sequential/Pipe/Stream is not very essential for the programmer? Would it be a decent default to just always go with Pipe or Stream: slight cost in hardware size and generally the best performance? Then this can be fine-tuned later if needed.

How is Reduce operation parallelized in Spatial implementation? Is it similar to the work-efficient Scan that was discussed a while back in Data-Parallel Thinking lecture, except that we return the last element, instead of the whole scanned array?

@sirah my understanding is that it's parallelized through pipelining and essentially duplicating the hardware necessary for the algorithm/controller as in Slide 26
Please log in to leave a comment.
During lecture, there was a point that specialized processor has no threads whereas generalized processor has threads. In some sense, I think the parallelism from these specialized processor inherently comes from the Foreach and Reduce primitives provided by the hardware language.
What are ways these (par P) statements gets mapped to underlying hardware? Are they transformed into logic gates with inherent parallelism during instruction execution by the hardware?