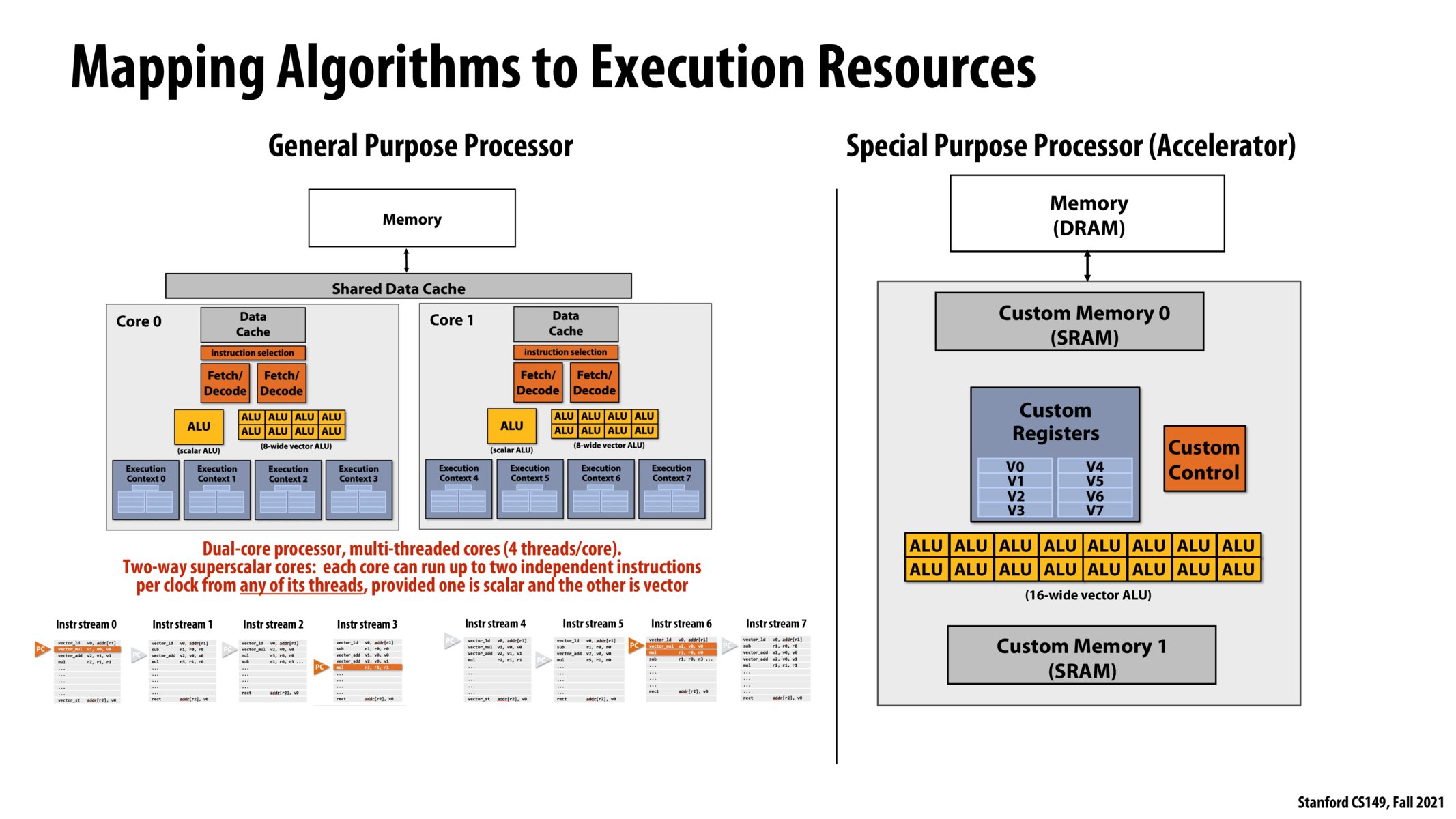


How does SRAM compare to regular data caches in terms of transfer speed and typical capacity/cost requirements?

I believe SRAM is the actual memory used in most CPU caches: https://en.wikipedia.org/wiki/Static_random-access_memory#In_computers.
Interestingly, some CPUs (mostly game consoles) use eDRAM (https://en.wikipedia.org/wiki/EDRAM), which is DRAM integrated onto the same module as the processor, and gives better density than SRAM (and higher speeds) at the penalty of additional fabrication cost.

@gmukobi do you know to what extent the program is "baked into the hardware"? As in, does the custom control unit essentially store a dump of the operations it needs to perform, or are the operations store elsewhere in the chip and the custom control unit knows how to retrieve them?

The fact that the special purpose processor (accelerator) illustrated in the right hand side graph doesn't have instruction selection and fetch/decode modules is an example of how hardware systems often trade off flexibility/easy to program with performance (e.g. the picture on the previous slide).

I was also wondering the implementation of how the instructions are hardcoded s.t. you don't need the fetch/decode / arbitrary instruction execution overhead @sanjayen

Typically in specialized hardware, there is no threading. (So no atomicity, barriers and etc)
Please log in to leave a comment.
From lecture: One important thing the special purpose accelerator doesn't have that the general processor does is instruction selection/fetching/decoding hardware. That's because a fully completed hardware accelerator (at least as shown here) is incapable of running arbitrary instructions from memory--the program that it will run is baked into the hardware itself through the custom control unit shown here and other mechanisms.