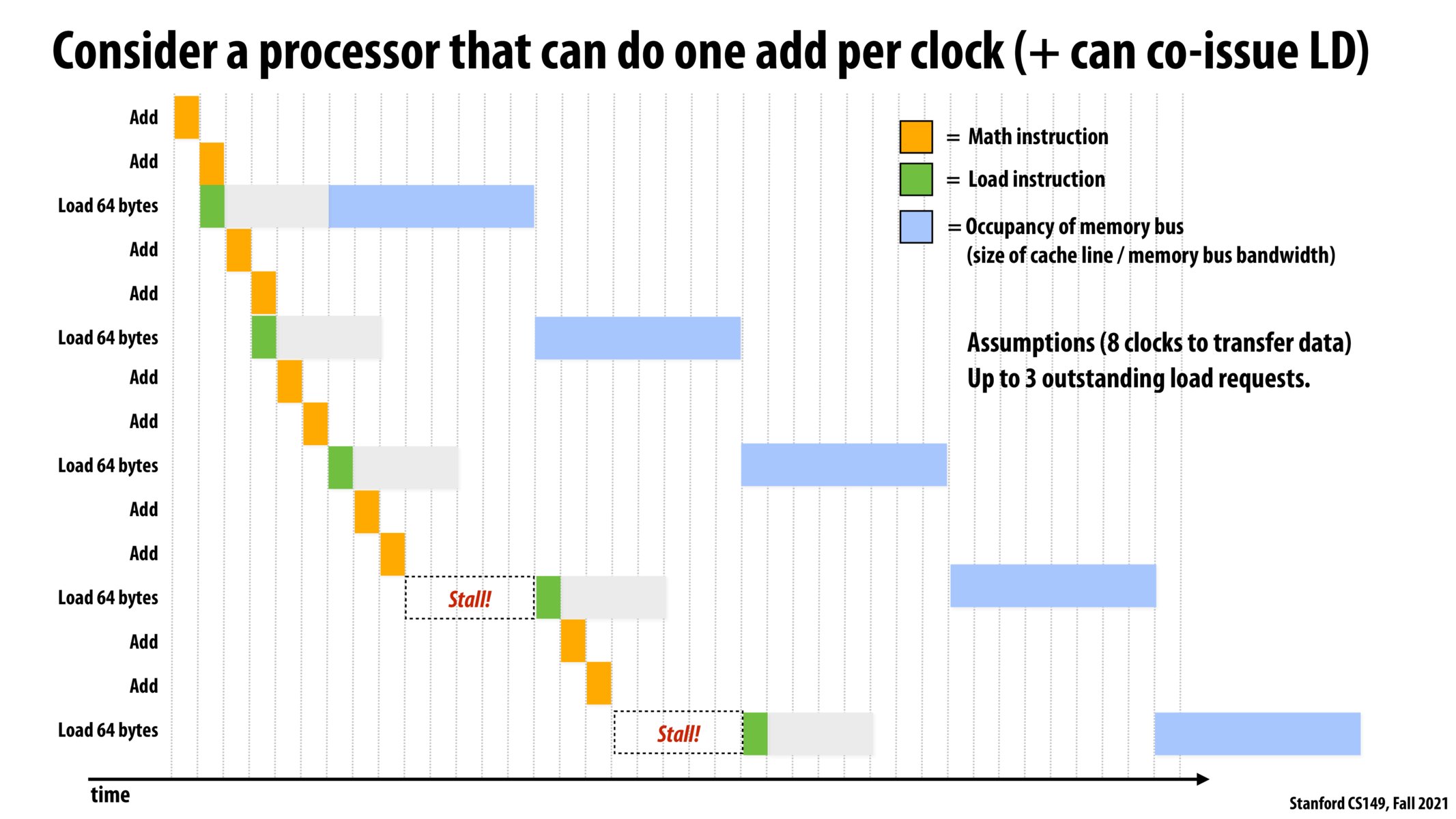


I was a little confused as to what the grey region referred to specifically. I understand that it represents the time it takes for data to start being transferred from memory, but what steps take place during that time?

As Prof. Kayvon said, the grey areas are where the executed load instruction is "conveyed" to the memory. The total memory access latency has been divided here into the grey and blue parts for illustration. The grey part is the one that does not need (and therefore does not block) the memory bus, whereas the blue one is.

Why does it take so much time for the load instruction to be "conveyed"? I thought the main reason latency for loads is so high is because the memory bus is blocked.

From the slide, in the first 2 rounds, there is 0 delay, i.e. load happens at the same time with add; in 3rd round, load happens 1 clock after add. Why is the first two rounds different from the 3rd?
@jaez. In this example, there is an assumption that there can only be a fixed number (in this case 2) number of outstanding memory requests at once. Therefore, if there are 2 outstanding LD requests, the next LD request can't be performed until one of the outstanding requests finishes.
If we go back to the laundry example, it's like saying there can only be so many loads of wet laundry stacked up waiting to be tried.

Are store instructions also using the same bandwidth as load instructions? Conceptually, the data flow is in the opposite direction - does memory bandwidth work the same way in both directions?
Are there physical limits to how much memory bandwidth can be increased?

Is the stall happening because you can't load while another thread is in the blue region? If so, why does it stall before loading at that spot and not the one before?

@laimagineCS149 this is very implementation specific but I can tell you for sure that read bandwidth can be different than write bandwidth, tho these numbers are usually very close.

Yeah @victor I believe that the memory bus works as a separate system from the processor instructions.

I am a bit confused about the difference between hiding latency and bandwidth-bound execution. In this example, if there were simply more math instructions in between every memory load, would this actually cover latency? Perhaps a code example would help. Thank you!

I understand that loading from memory is slow, but what about from cache? can we load data from memory to cache to speed up the loading speed? From the diagram, the blue strips are "size of the cache line/memory bus bandwidth". Aren't cache lines faster than memory buses?

How is speed up calculated if we increase the bandwidth? Particularly if the processor becomes arithmetic bound prior to utilizing the max speed up given by the increased bandwidth.
Please log in to leave a comment.
In this example we don't seem to have enough computational work to hide the latency as we did with the example in the previous lecture (slide 73).